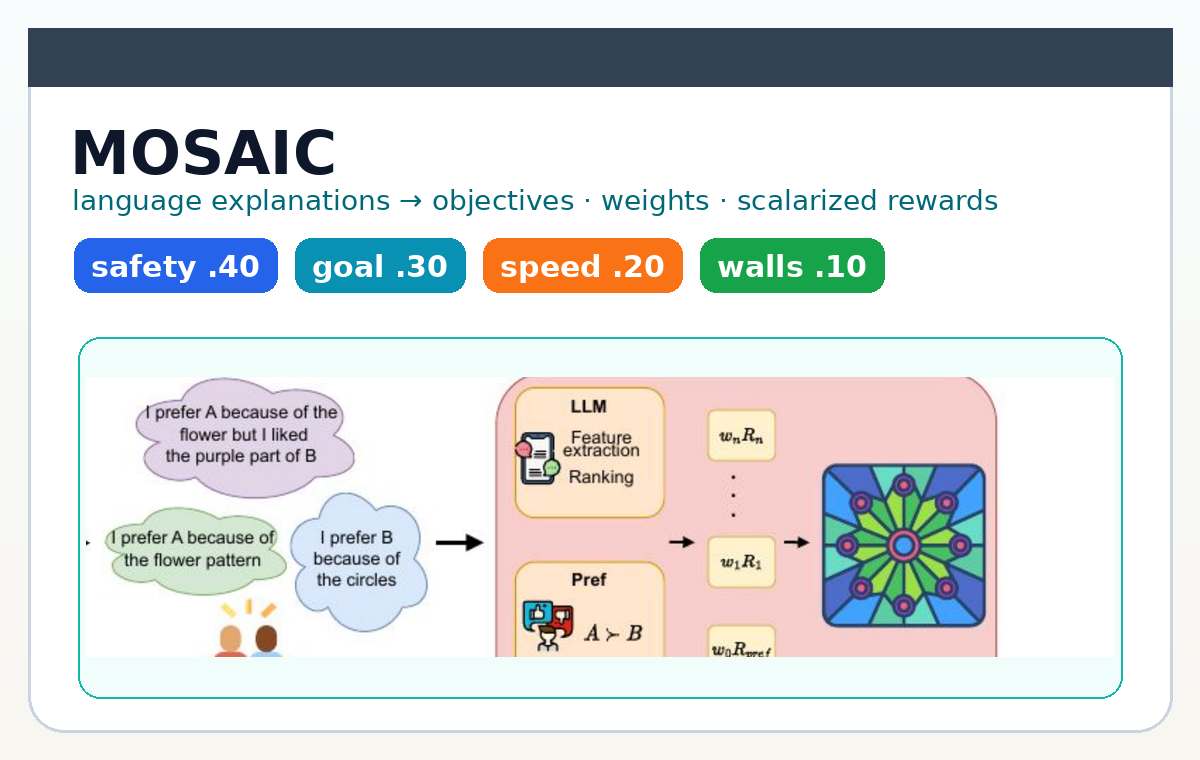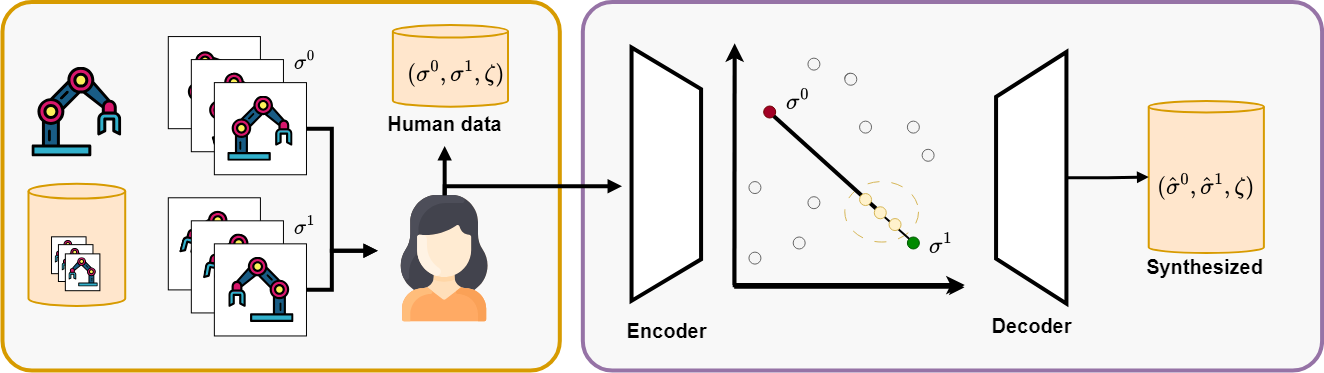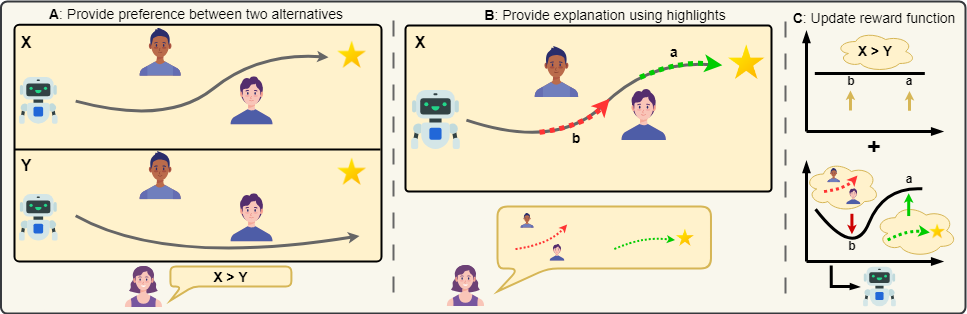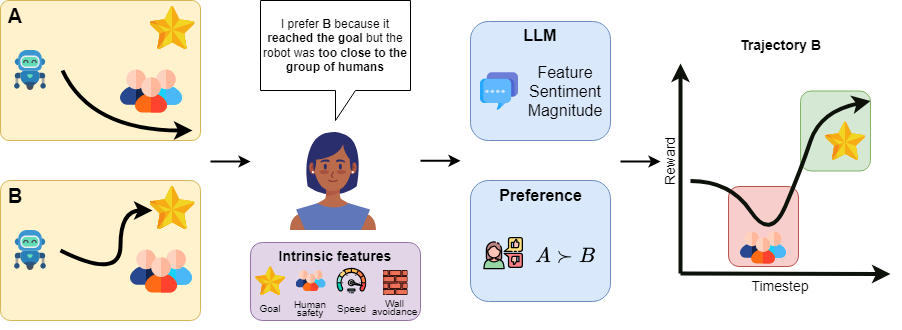
2026
Uncertainty Quantification for Flow-Based Vision-Language-Action Models
arXiv preprint arXiv:2606.18043, 2026
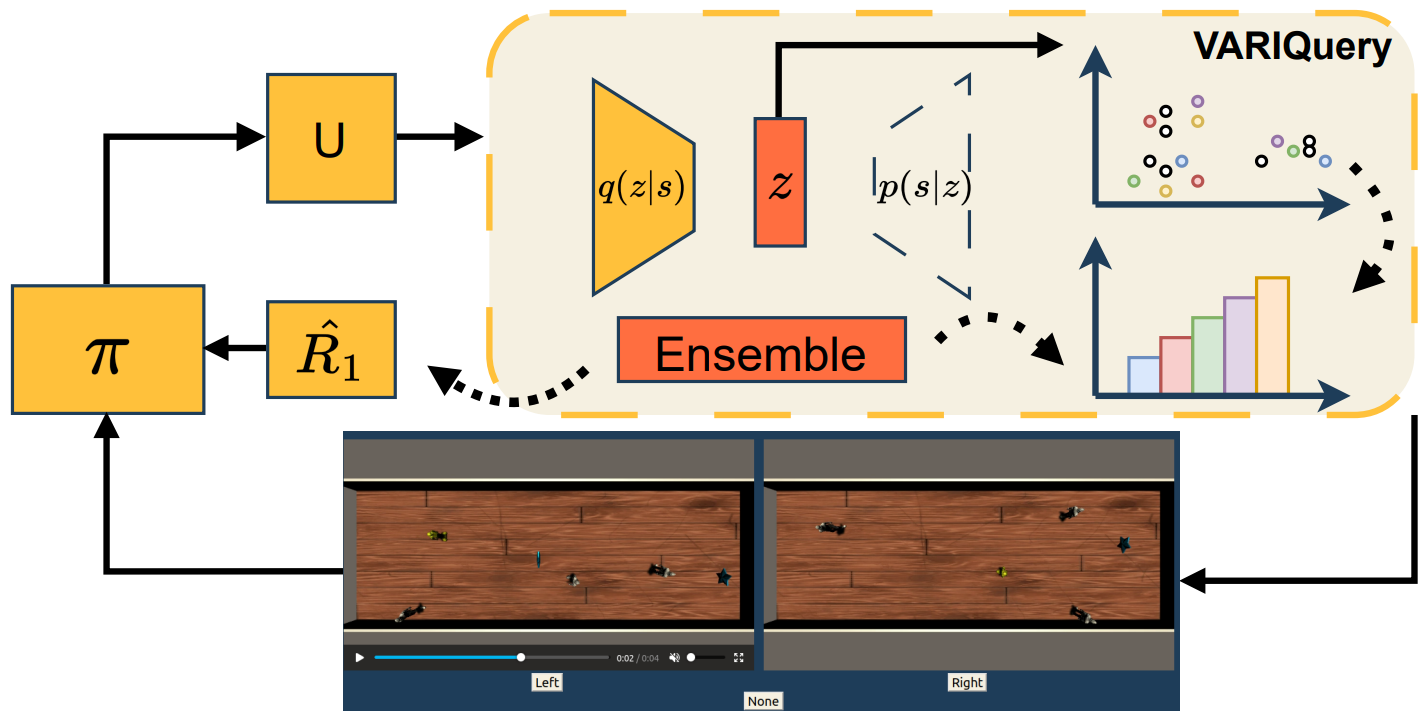
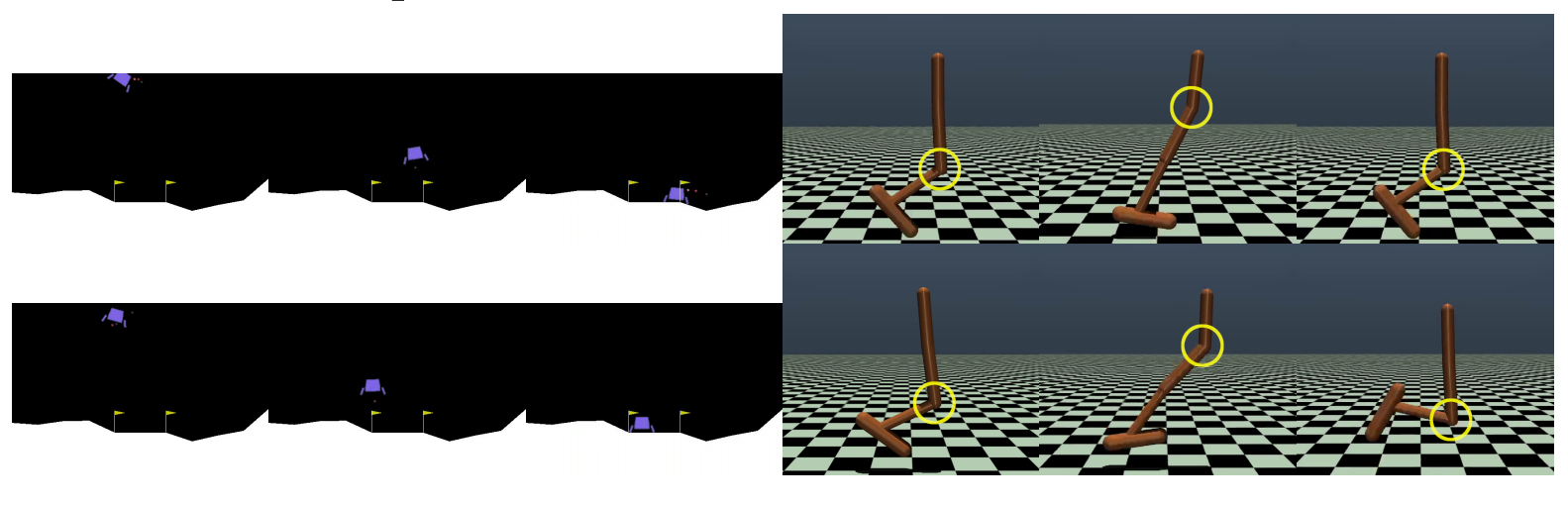
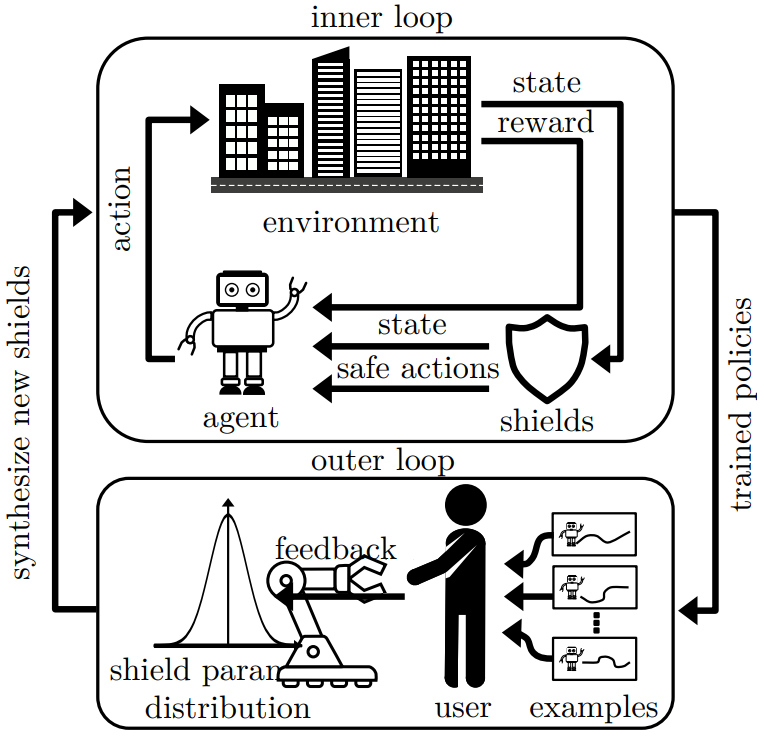
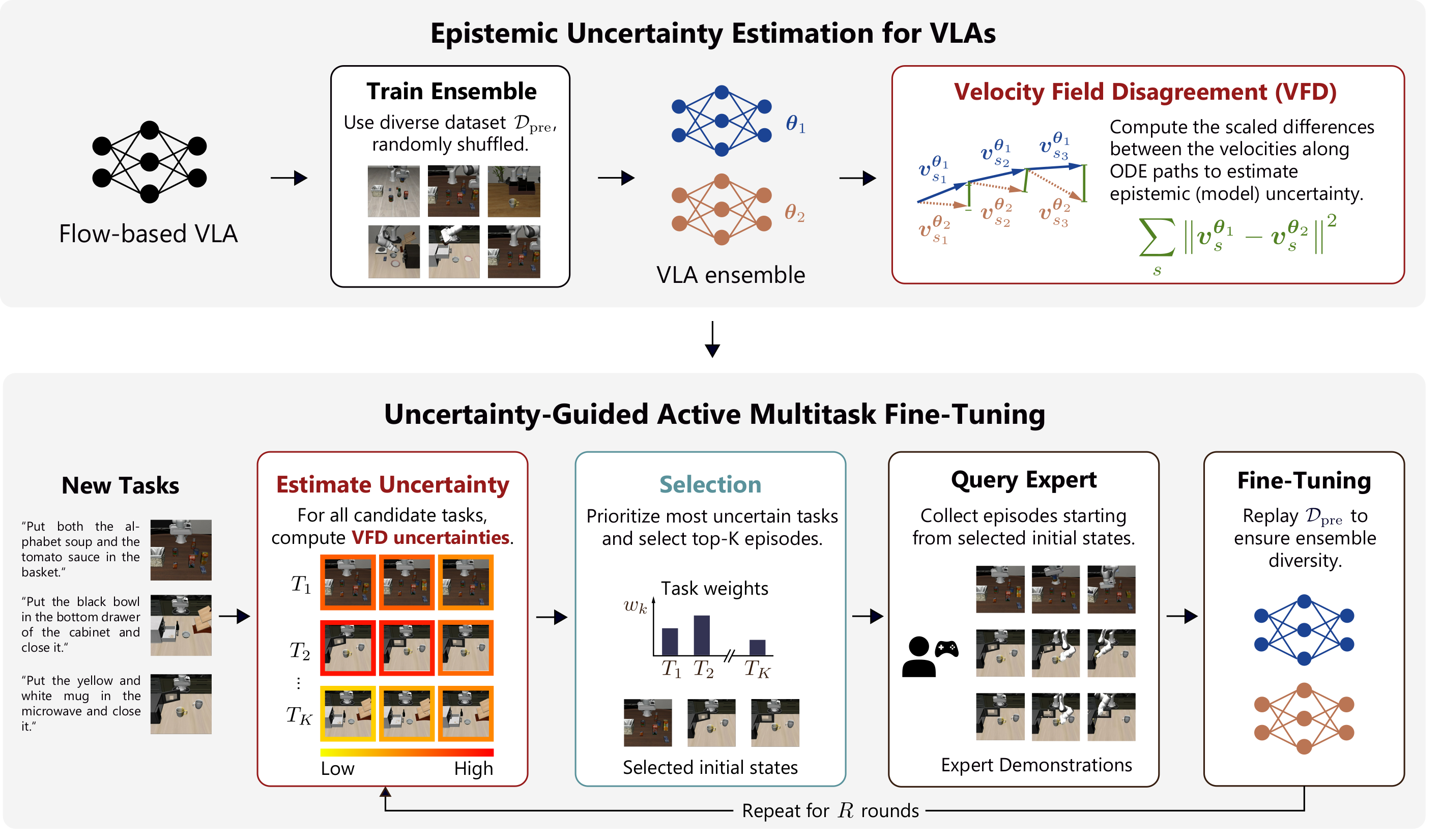
Introduces Velocity-Field Disagreement (VFD) for epistemic uncertainty in flow-based VLAs and SAVE, an uncertainty-guided active fine-tuning framework that needs at least 22% fewer expert demonstrations than baselines.