Jump to selected publications or workshops.
* (asterisk)- signals authors contributed equally.
Selected Publications
SEQUEL: Semi-Supervised Preference-based RL with Query Synthesis via Latent Interpolation
Daniel Marta*, Simon Holk*, Christian Pek, Jana Tumova, and Iolanda Leite
ICRA'24
By utilizing semi-supervised learning we can improve the sample-efficiency by augmenting the preferences provided by humans.
We train a VAE to learn a latent representation and thereafter synthesise new queries from existing ones by interpolating the
trajectory pairs. The idea is that if a user prefers traj A over traj B, even if they are a bit closer (like 10%) they would
still prefer it. This helps the feedback generalize better.
POLITE: Preferences Combined with Highlights in Reinforcement Learning
Simon Holk, Daniel Marta, and Iolanda Leite
ICRA'24 - Nominated for best HRI paper, best student paper, and best conference paper!
This paper aims to improve the granularity of preference-based feedback by adding temporal trajectory segmentation
to highlight positive and negative parts. This helps avoid the uniform assignment of responsibility across the whole trajectory
while it might just be some part that was actually preferred. The highlights are then optimized as an auxiliary task ensuring
a improved shared representation.
PREDILECT: Preferences Delineated with Zero-Shot Language-based Reasoning in Reinforcement Learning
Simon Holk*, Daniel Marta*, and Iolanda Leite
HRI'24
This paper aims to utilize the zero-shot capabilities of LLM in order to increase the granularity
of preference-based feedback by extending my previous work. By letting the user give optional auxiliary
textual descriptions of their preference we ensure that the reward function align with what the human
actually wants as well as improve the sample-efficiency by avoiding over-sampling.
VARIQuery: VAE Segment-based Active Learning for Query Selection in Preference-based Reinforcement Learning
Daniel Marta*, Simon Holk*, Christian Pek, Jana Tumova, and Iolanda Leite
IROS'23
This paper addresses the
often-overlooked aspect of query selection, which is closely
related to active learning (AL). We propose a novel query
selection approach that leverages variational autoencoder (VAE)
representations of state sequences. In this manner, we formulate
queries that are diverse in nature while simultaneously taking
into account reward model estimations.
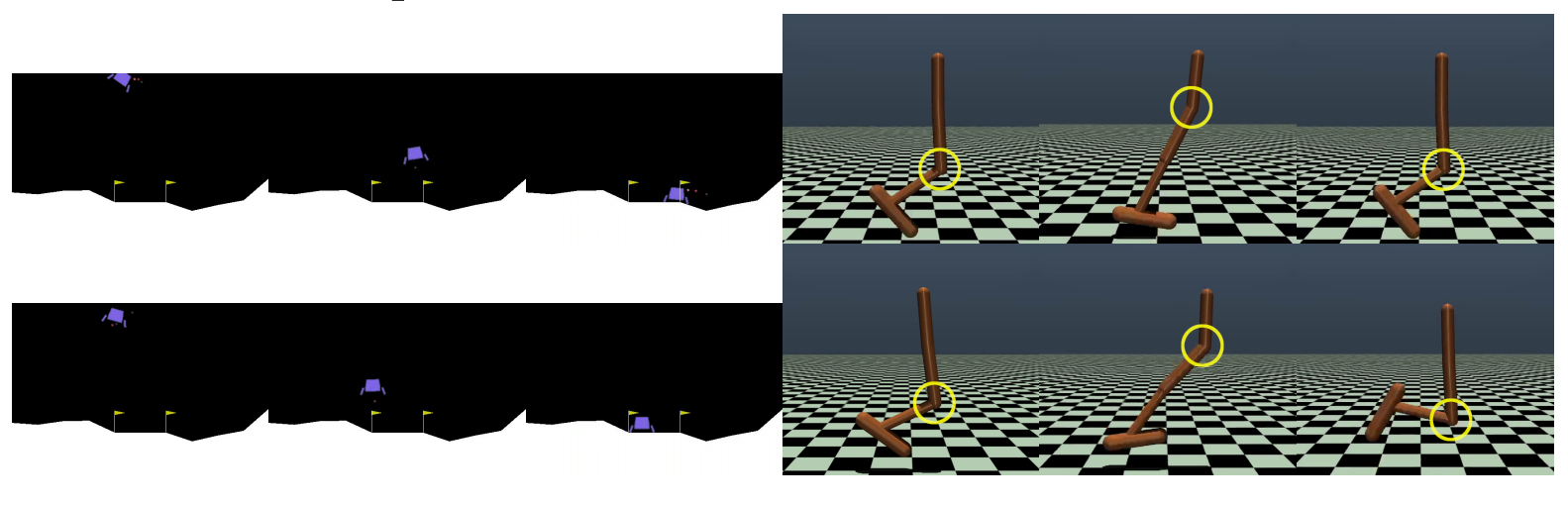
Aligning Human Preferences with Baseline Objectives in Reinforcement Learning
Daniel Marta, Simon Holk, Christian Pek, Jana Tumova, and Iolanda Leite
ICRA'23
By considering baseline objectives to be designed
beforehand, we are able to narrow down the policy space, solely
requesting human attention when their input matters the most.
To allow for control over the optimization of different objectives,
our approach contemplates a multi-objective setting. We achieve
human-compliant policies by sequentially training an optimal
policy from a baseline specification and collecting queries on
pairs of trajectories.
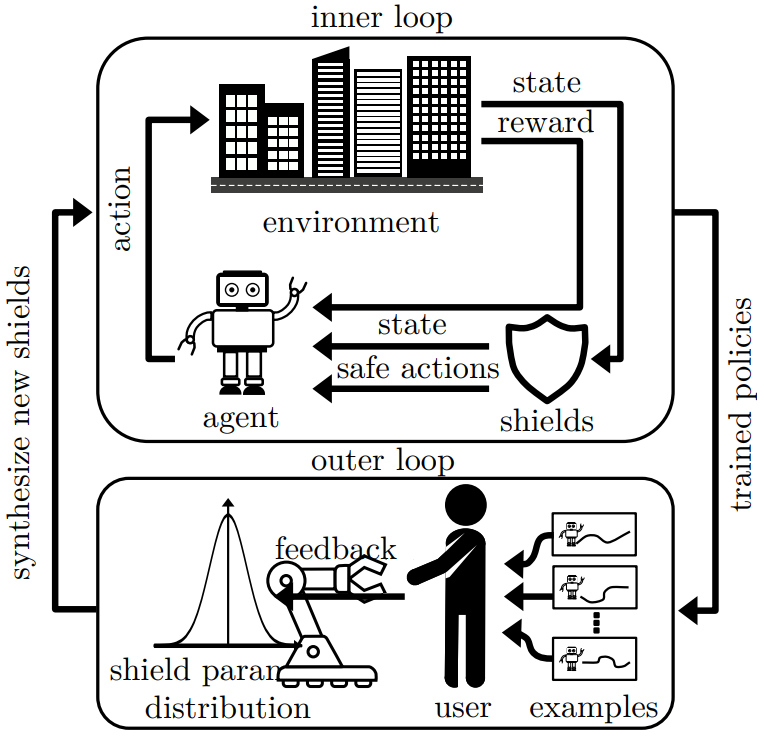
Human-feedback shield synthesis for perceived safety in deep reinforcement learning
Daniel Marta, Christian Pek, Gaspar I. Melsion, Jana Tumova, and Iolanda Leite
RAL'21
To obtain policies that are perceived
as safe, we propose a shield synthesis framework with two
distinct loops: (1) an inner loop that trains policies with a set
of actions that is constrained by shields whose conservativeness
is parameterized, and (2) an outer loop that presents example
rollouts of the policy to humans and collects their feedback
to update the parameters of the shields in the inner loop.
Workshops
Human-Centric Autonomous Systems With LLMs for User Command Reasoning
Yi Yang, Qingwen Zhang, Ci Li, Daniel Marta, Nazre Batool, John Folkesson
WACV LLVM-AD Workshop'24 - Best student paper award!
To ensure that the autonomous system
meets the user’s intent, it is essential to accurately discern
and interpret user commands, especially in complex or
emergency situations. To this end, we propose to leverage
the reasoning capabilities of Large Language Models
(LLMs) to infer system requirements from in-cabin users’
commands. Through a series of experiments that include
different LLM models and prompt designs, we explore
the few-shot multivariate binary classification accuracy
of system requirements from natural language textual
commands.
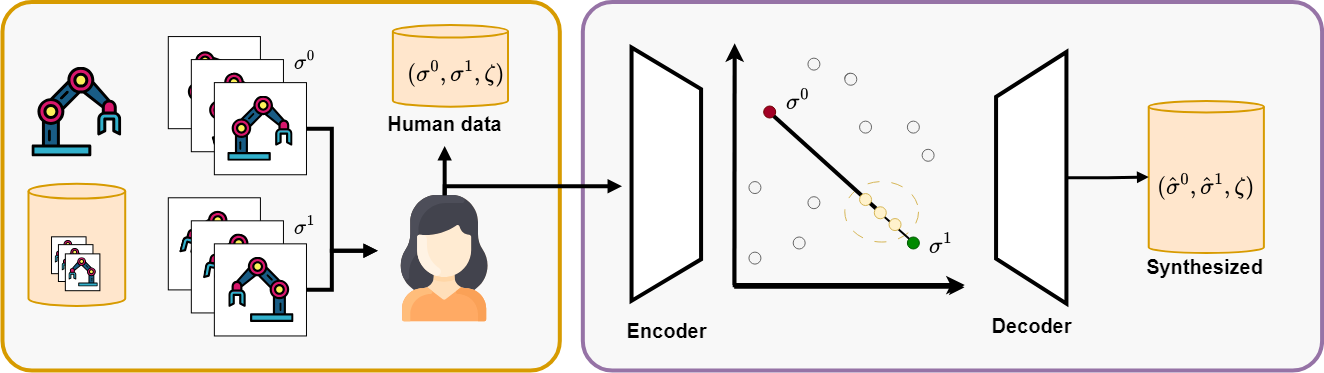
Daniel Marta*, Simon Holk*, Christian Pek, Jana Tumova, and Iolanda Leite
ICRA'24
By utilizing semi-supervised learning we can improve the sample-efficiency by augmenting the preferences provided by humans. We train a VAE to learn a latent representation and thereafter synthesise new queries from existing ones by interpolating the trajectory pairs. The idea is that if a user prefers traj A over traj B, even if they are a bit closer (like 10%) they would still prefer it. This helps the feedback generalize better.
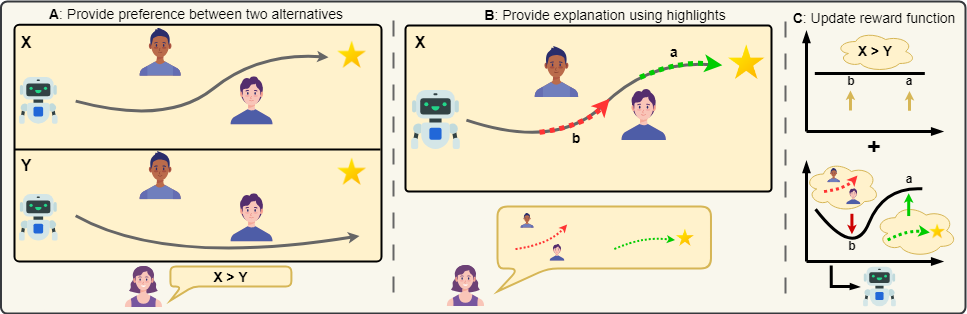
Simon Holk, Daniel Marta, and Iolanda Leite
ICRA'24 - Nominated for best HRI paper, best student paper, and best conference paper!
This paper aims to improve the granularity of preference-based feedback by adding temporal trajectory segmentation to highlight positive and negative parts. This helps avoid the uniform assignment of responsibility across the whole trajectory while it might just be some part that was actually preferred. The highlights are then optimized as an auxiliary task ensuring a improved shared representation.
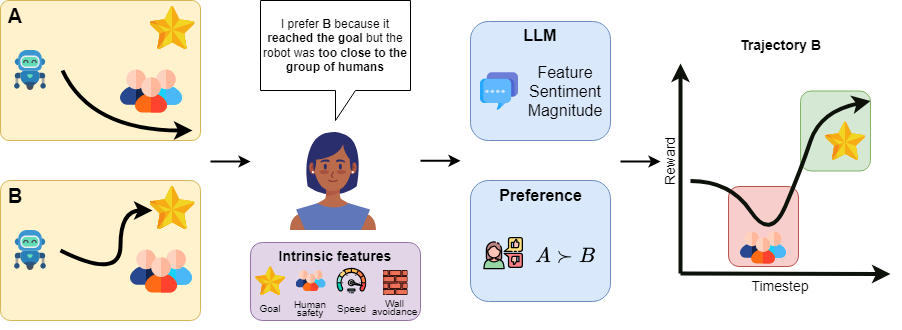
Simon Holk*, Daniel Marta*, and Iolanda Leite
HRI'24
This paper aims to utilize the zero-shot capabilities of LLM in order to increase the granularity of preference-based feedback by extending my previous work. By letting the user give optional auxiliary textual descriptions of their preference we ensure that the reward function align with what the human actually wants as well as improve the sample-efficiency by avoiding over-sampling.
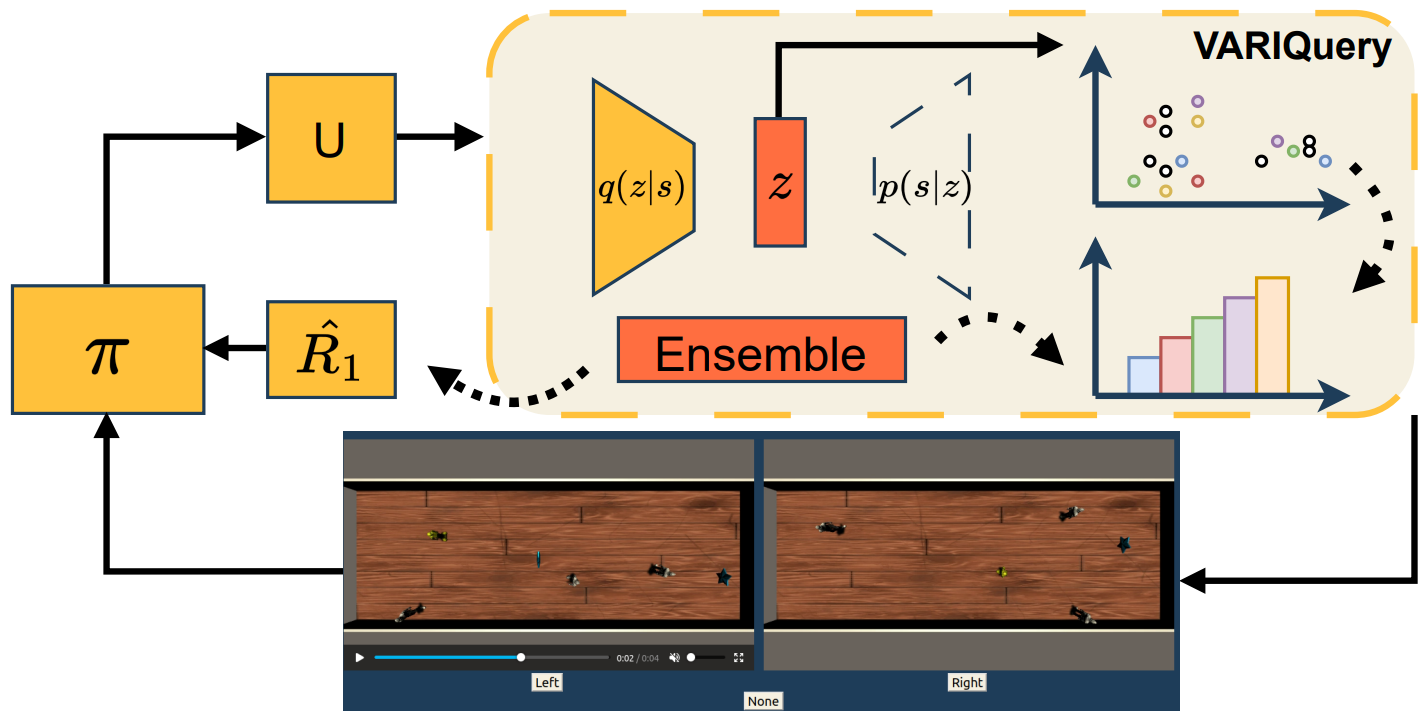
Daniel Marta*, Simon Holk*, Christian Pek, Jana Tumova, and Iolanda Leite
IROS'23
This paper addresses the often-overlooked aspect of query selection, which is closely related to active learning (AL). We propose a novel query selection approach that leverages variational autoencoder (VAE) representations of state sequences. In this manner, we formulate queries that are diverse in nature while simultaneously taking into account reward model estimations.
Daniel Marta, Simon Holk, Christian Pek, Jana Tumova, and Iolanda Leite
ICRA'23
By considering baseline objectives to be designed beforehand, we are able to narrow down the policy space, solely requesting human attention when their input matters the most. To allow for control over the optimization of different objectives, our approach contemplates a multi-objective setting. We achieve human-compliant policies by sequentially training an optimal policy from a baseline specification and collecting queries on pairs of trajectories.
Daniel Marta, Christian Pek, Gaspar I. Melsion, Jana Tumova, and Iolanda Leite
RAL'21
To obtain policies that are perceived as safe, we propose a shield synthesis framework with two distinct loops: (1) an inner loop that trains policies with a set of actions that is constrained by shields whose conservativeness is parameterized, and (2) an outer loop that presents example rollouts of the policy to humans and collects their feedback to update the parameters of the shields in the inner loop.

Yi Yang, Qingwen Zhang, Ci Li, Daniel Marta, Nazre Batool, John Folkesson
WACV LLVM-AD Workshop'24 - Best student paper award!
To ensure that the autonomous system meets the user’s intent, it is essential to accurately discern and interpret user commands, especially in complex or emergency situations. To this end, we propose to leverage the reasoning capabilities of Large Language Models (LLMs) to infer system requirements from in-cabin users’ commands. Through a series of experiments that include different LLM models and prompt designs, we explore the few-shot multivariate binary classification accuracy of system requirements from natural language textual commands.